Neaural Network Pruning Algorithm
Overview
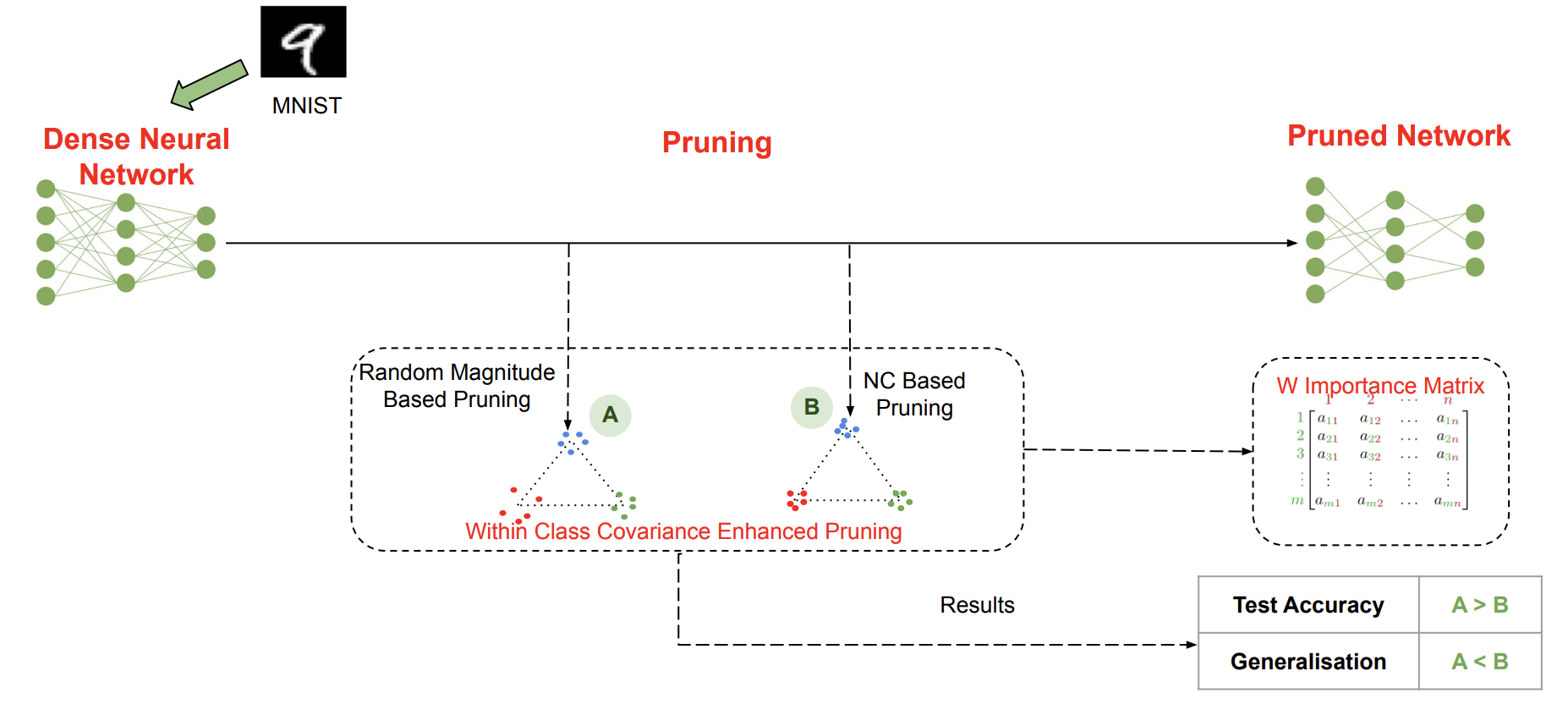
This project implements a novel pruning technique inspired by Neural Collapse (NC) geometry to enhance the robustness of pruned neural networks, particularly in imbalanced datasets. The proposed method utilizes the within-class scatter matrix to maintain class-separability during pruning, ensuring that minority class features are retained. This approach addresses the bias introduced by traditional pruning methods, which tend to favor majority classes in imbalanced data.
Key Features
- Neural Collapse-Inspired Pruning: A pruning technique using the within-class scatter matrix to preserve class-separability in the pruned network.
- Bias Mitigation: Reduces bias towards majority classes in imbalanced datasets by maintaining minority class features.
- Robustness Testing: Includes robustness testing against noisy data using perturbation sensitivity.
Research Questions
- Can Neural Collapse-inspired pruning improve performance under imbalanced datasets?
- Does this pruning method enhance model robustness?
Contributions
- Analysis of pruned neural network performance under different pruning techniques.
- Introduction of a geometry-based pruning algorithm inspired by Neural Collapse.
- Evaluation of robustness and generalization in pruned networks.
Proposed Solution